快速上手
本文将通过一个实际的例子,演示如何在 OpenBayes 上使用 vLLM 部署大语言模型。我们将部署 DeepSeek-R1-Distill-Qwen-1.5B 模型,这是一个基于 Qwen 的轻量级模型。
模型介绍
DeepSeek-R1-Distill-Qwen-1.5B 是一个轻量级的中英双语对话模型:
- 1.5B 参数量,单卡即可部署
- 最小显存要求:3GB
- 推荐显存配置:4GB 及以上

在模型训练中开发和测试
创建一个新的模型训练
- 选择 RTX 4090 算力
- 选择 vLLM 0.7.2 基础镜像
- 在数据绑定中选择 DeepSeek-R1-Distill-Qwen-1.5B 模型,绑定到
/openbayes/input/input0



准备启动脚本 start.sh
容器启动后,准备如下的 start.sh 脚本。
#!/bin/bash
# 获取 GPU 数量
GPU_COUNT=$(nvidia-smi --query-gpu=name --format=csv,noheader | wc -l)
# 设置端口,模型部署默认暴露的端口为 80 而模型训练默认暴露的端口为 8080
PORT=8080
if [ ! -z "$OPENBAYES_SERVING_PRODUCTION" ]; then
PORT=80
fi
# 启动 vLLM 服务
echo "Starting vLLM service..."
vllm serve /openbayes/input/input0 \
--served-model-name DeepSeek-R1-Distill-Qwen-1.5B \
--disable-log-requests \
--trust-remote-code \
--host 0.0.0.0 --port $PORT \
--gpu-memory-utilization 0.98 \
--max-model-len 8192 --enable-prefix-caching \
--tensor-parallel-size $GPU_COUNT
在容器中测试服务
bash start.sh

下面是一个测试模型推理的 curl 请求示例:
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{
"role": "user",
"content": "请用中文解释什么是大语言模型"
}
],
"temperature": 0.7,
"max_tokens": 100
}'
在 Jupyter 中打开一个新的终端(Terminal),粘贴上面的 curl 命令进行测试:
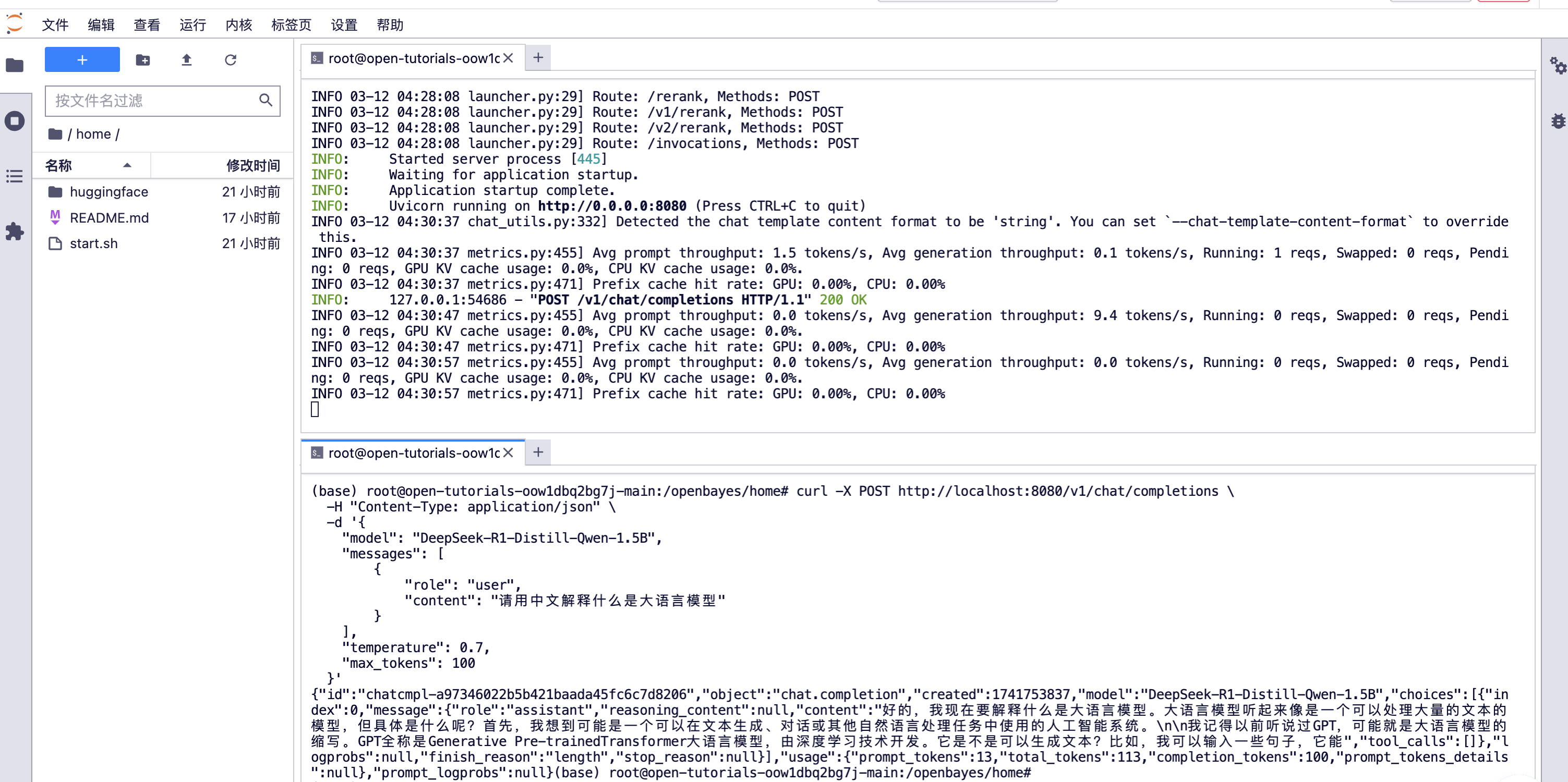
在模型训练中测试时使用的是 8080 端口,但在模型部署中会自动切换到 80 端口。这是因为 OpenBayes 的模型部署服务要求必须使用 80 端口对外提供服务。
部署模型服务
完成模型训练和测试后,可以通过以下两种方式将模型转化为可访问的部署服务:
方式一:一键部署模型(推荐)
OpenBayes 提供了便捷的"一键部署"功能,让你无需重复配置即可快速将模型训练转化为模型部署服务。
使用一键部署功能
- 在模型训练详情页面,找到右上角的"一键部署"按钮
- 确认部署配置信息(系统会自动继承训练容器的配置)
- 点击"确认部署",系统会自动创建对应的模型部署服务
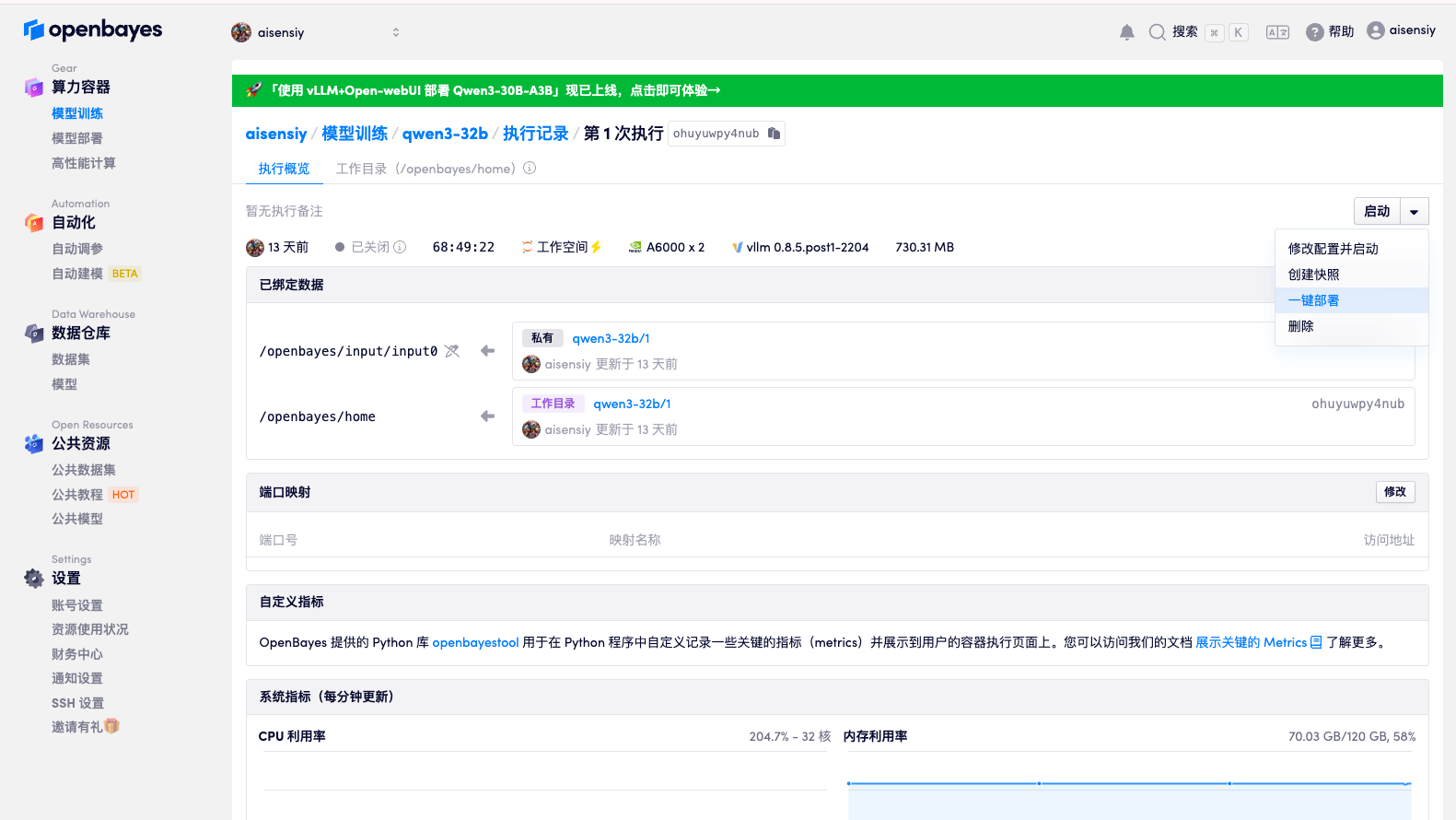
部署配置确认
系统会自动从原训练容器继承以下配置:
- 算力资源设置
- 基础镜像
- 工作空间数据
- 数据绑定关系
你可以在确认页面根据需要调整这些配置。
部署成功
提交后,系统会自动创建模型部署并启动服务。成功后会跳转到模型部署详情页,你可以立即使用在线测试工具验证接口。
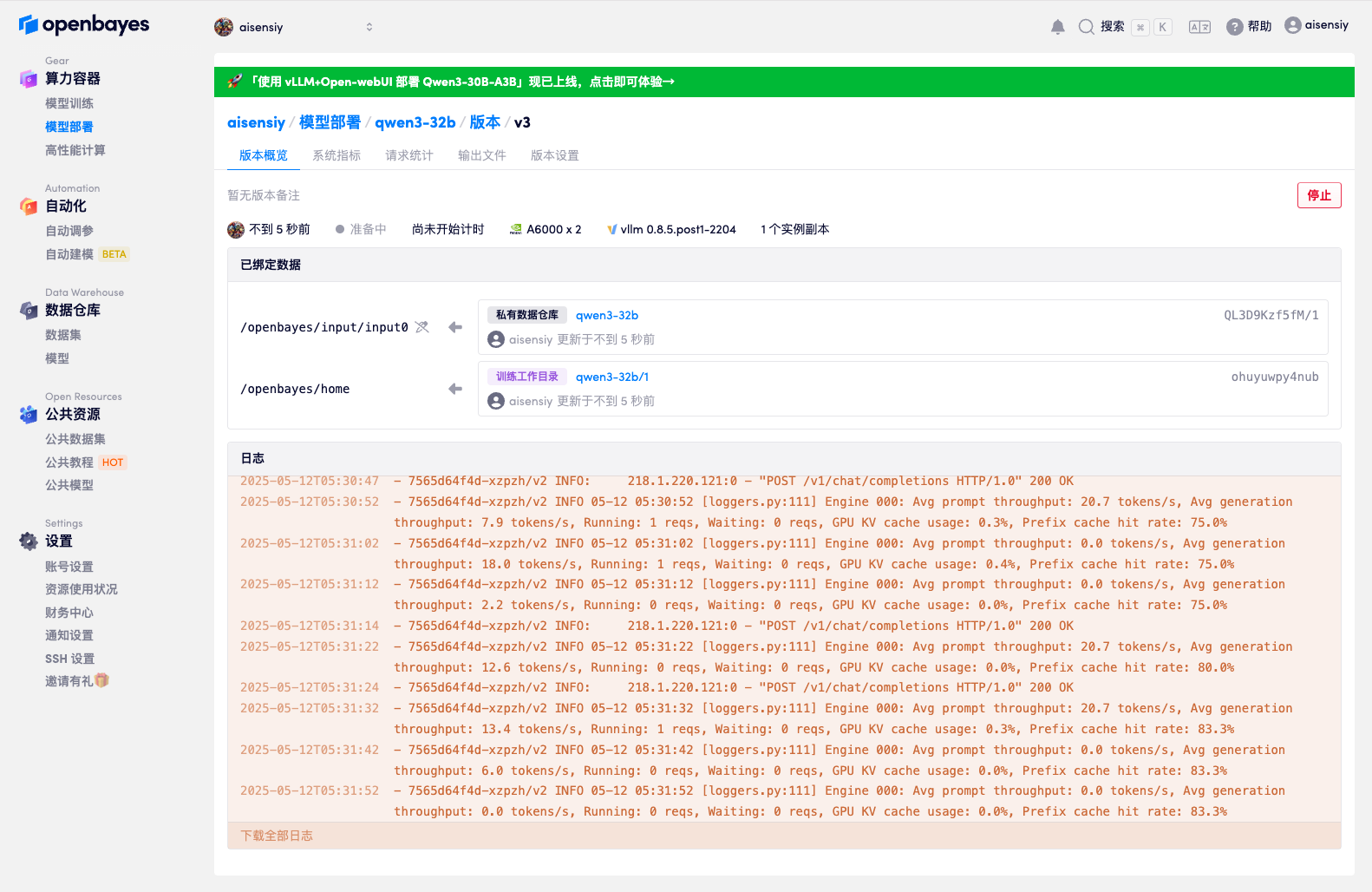
方式二:手动创建模型部署
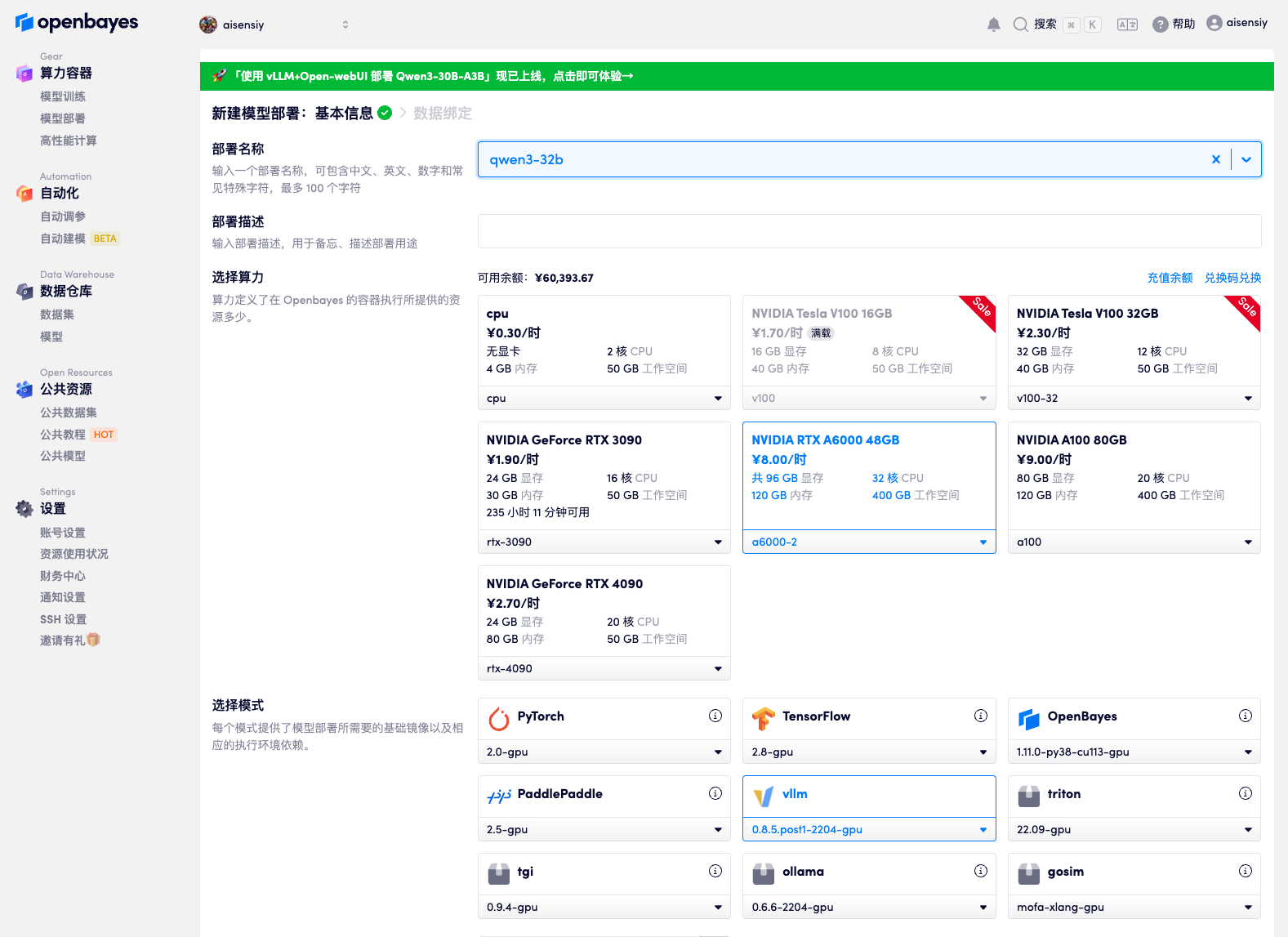
如果你需要更灵活地配置部署环境,或者想从头开始创建模型部署,可以按照以下步骤手动创建:
选择算力 - 选择镜像 - 绑定数据
- 选择 RTX 4090 算力
- 选择 vLLM 0.7.2 基础镜像
- 在数据绑定中选择 DeepSeek-R1-Distill-Qwen-1.5B 模型,绑定到
/openbayes/input/input0 - 将刚才容器的工作空间绑定到
/openbayes/home
创建 ServingVersion 时,必须至少有一个绑定挂载到 /openbayes/home(即 /output)。这个绑定源中还需要包含 start.sh,否则部署无法启动。
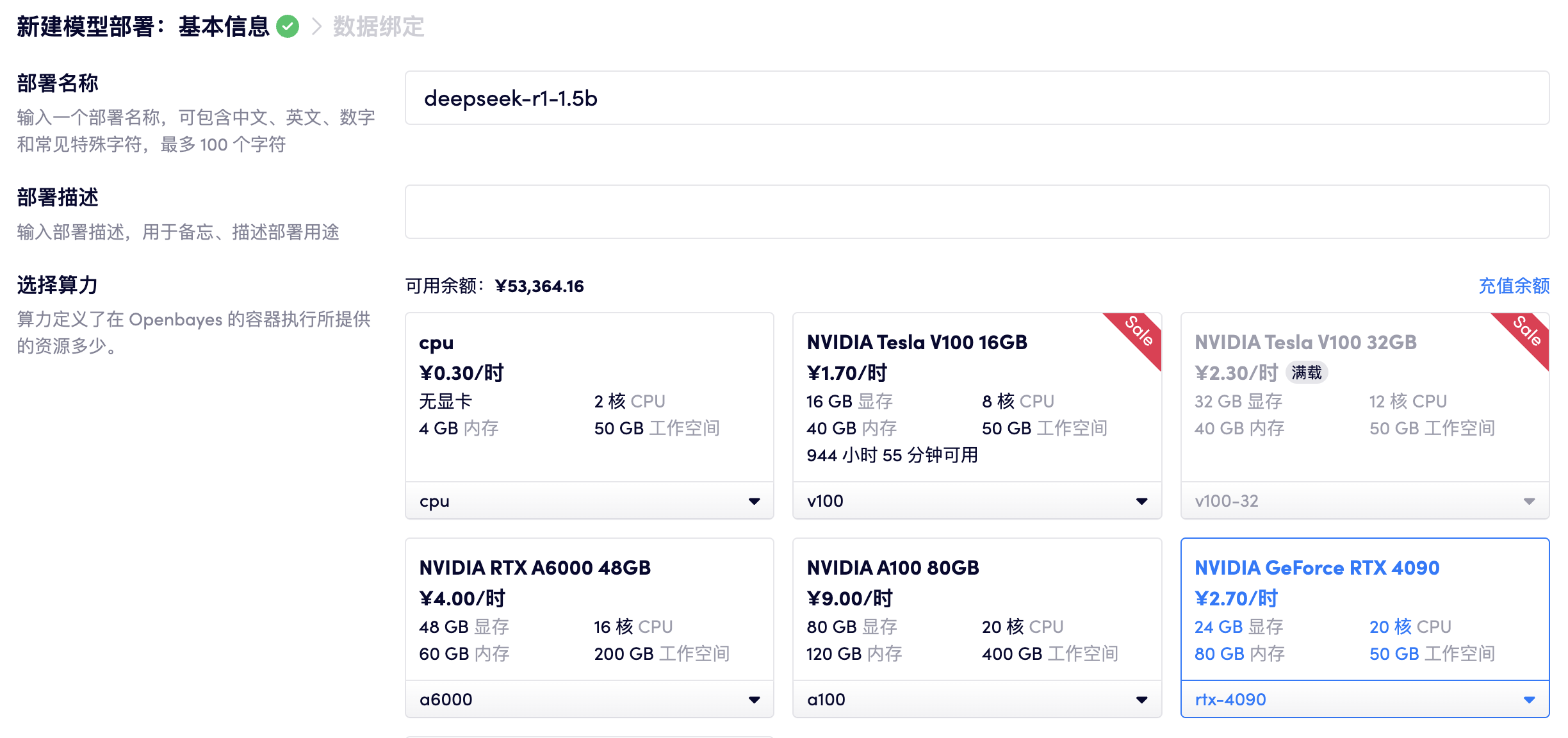


启动部署
点击「部署」等待模型部署变更为运行中。

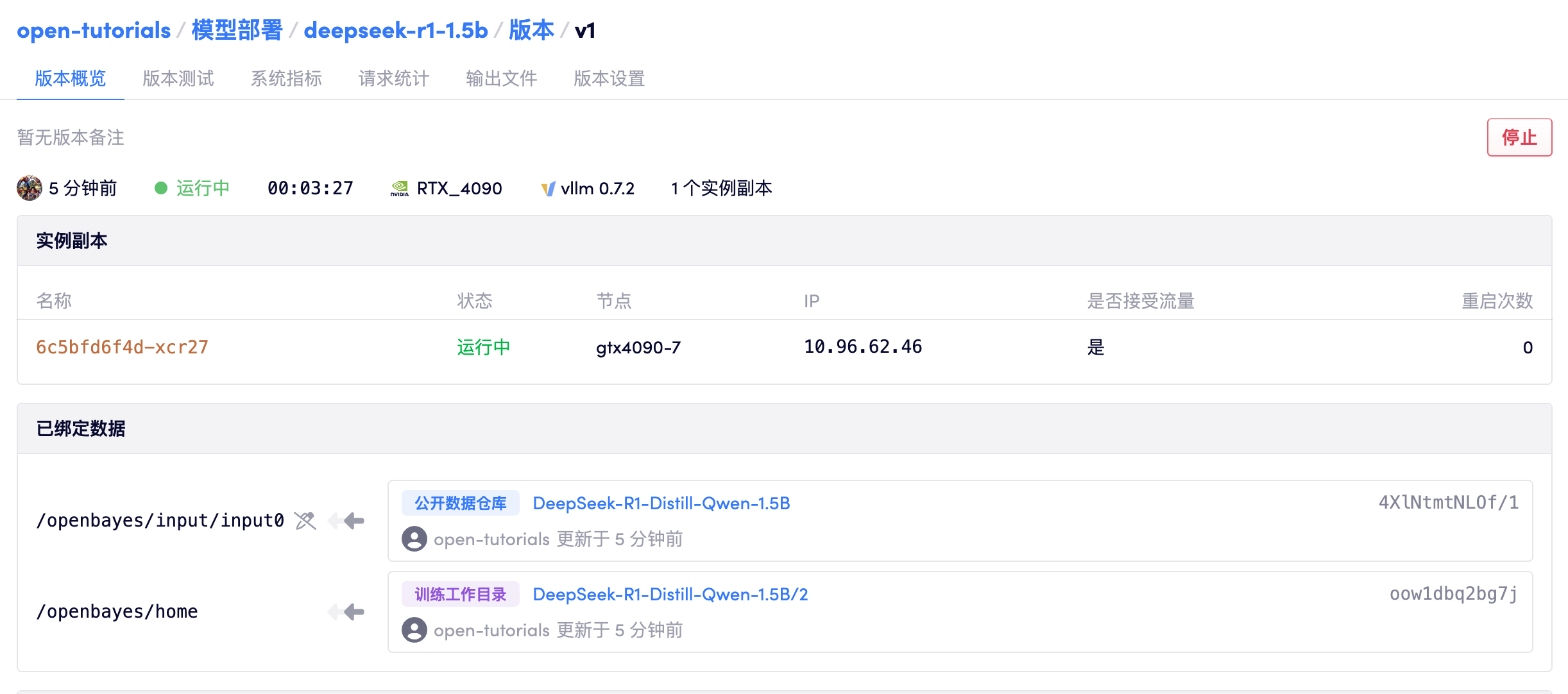
点击运行的模型部署版本,可以看到当前部署的详细内容已经日志。
在线测试
在模型部署详情页,OpenBayes 提供了一个在线测试工具,方便你在网页端可视化地编写和发送 HTTP 请求,快速测试模型接口,无需本地命令行或第三方工具。
你可以:
- 选择请求方法(如 GET、POST)
- 填写接口路径和参数
- 自定义请求头和请求体(支持 JSON 等格式)
- 一键发送请求,实时查看响应内容和响应头
- 支持流式输出,体验大模型的流式推理效果
GET 请求示例
用于获取模型信息或健康检查。选择 GET 方法,填写接口路径(如 /v1/models),点击发送即可查看模型列表或状态等信息。

POST 请求示例
用于与大语言模型进行对话。选择 POST 方法,路径填写 /v1/chat/completions,在请求体中输入对话内容(如下所示),点击发送即可体验模型回复。
{
"model": "qwen3-32b",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "北京的天气如何?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
],
"description": "The temperature unit to use"
}
},
"required": [
"location"
]
}
}
}
],
"tool_choice": "auto"
}

流式调用示例
用于体验大模型的流式推理效果。只需在 POST 请求体中添加 "stream": true 字段,发送请求后即可实时看到模型逐步输出的内容,适合需要边生成边消费结果的场景。
{
"model": "qwen3-32b",
"stream": true,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "北京的天气如何?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
],
"description": "The temperature unit to use"
}
},
"required": [
"location"
]
}
}
}
],
"tool_choice": "auto"
}

命令行测试
如果你更习惯使用命令行工具(如 curl),也可以参考以下方法进行接口测试:
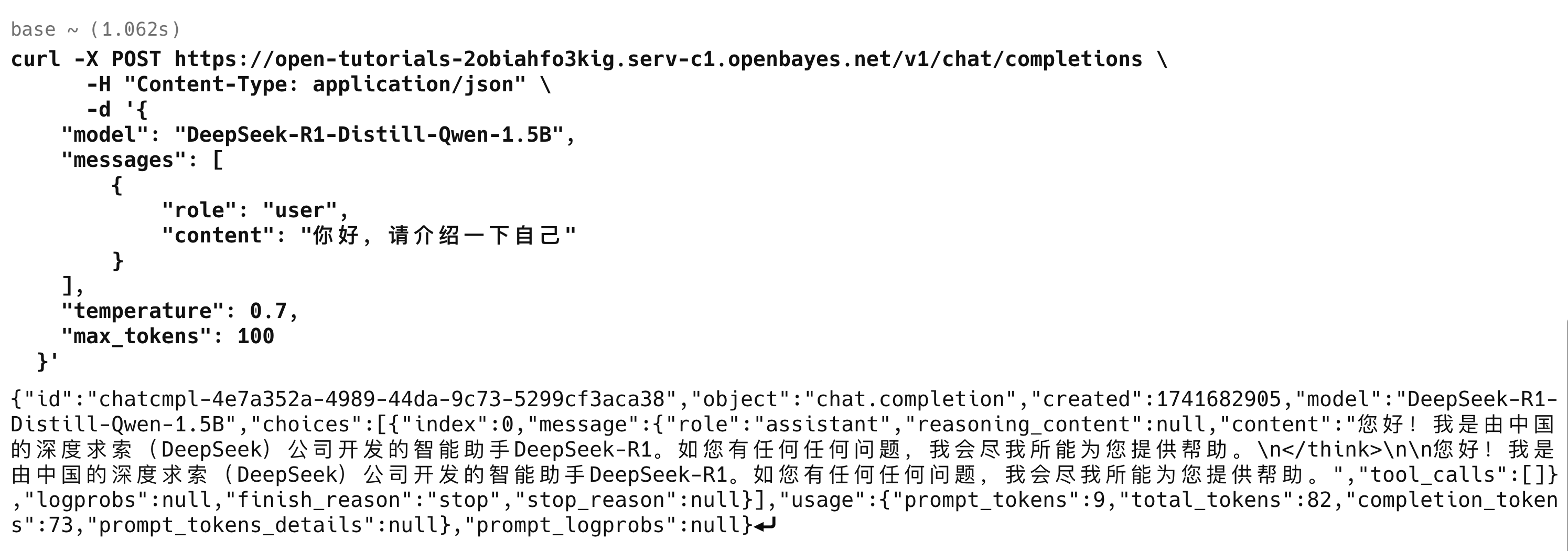
在模型部署页面上可以看到 OpenBayes 为模型部署生成的 url,复制 url 使用下面的命令行测试模型是否可用。
curl -X POST http://<模型部署的 url>/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{
"role": "user",
"content": "你好,请介绍一下自己"
}
],
"temperature": 0.7,
"max_tokens": 100
}'