算力容器数据绑定
可绑定的内容
在容器创建或者重启时,可以选择绑定数据到容器里,即使是规模巨大的数据集也可以绑定进来以文件系统的方式直接访问。可以绑定的内容包含以下几类:
- 公开数据集
- 个人私有的数据集
- 公开教程的工作目录
- 个人私有的执行的工作目录
- 上传新的代码
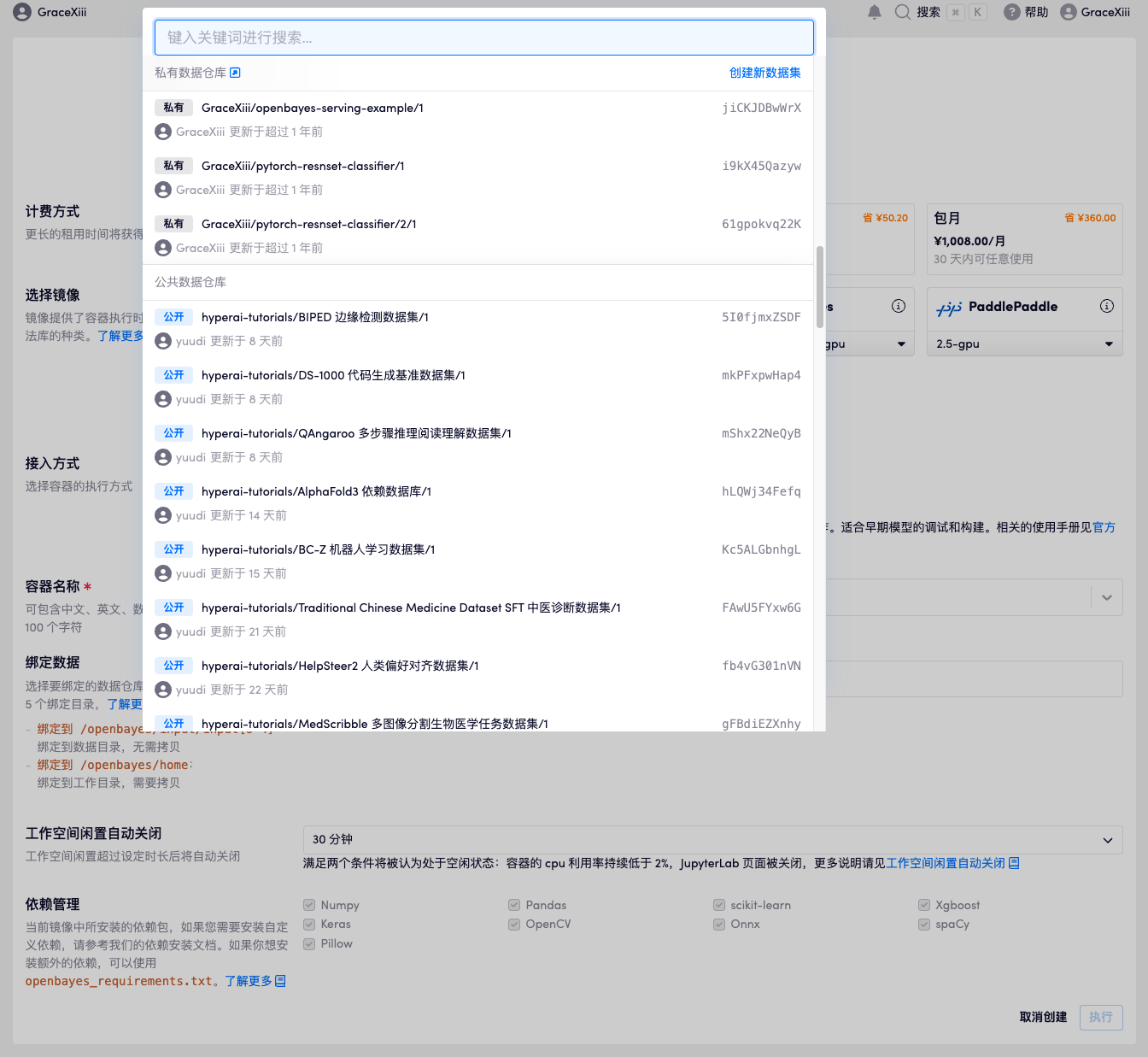
如下图所示,在容器的「数据绑定」界面,所有可供绑定的数据都会被列出,同时你也可以通过名称、ID 等字段进行筛选。
绑定到工作目录
每次容器执行任务时,都会创建一个独立的存储空间并绑定到 /openbayes/home 目录,这被称为其工作目录。此目录也以软链接的方式指向 /openbayes/home 目录。执行关闭后,工作目录中的内容会被保存下来,这就是所谓的执行「工作目录」。
请注意,绑定到工作目录实际上涉及到数据的复制过程,因此,容器的启动时间可能会因绑定的数据量的大小而变化,并且这也会占用工作目录的存储空间。
绑定到数据目录
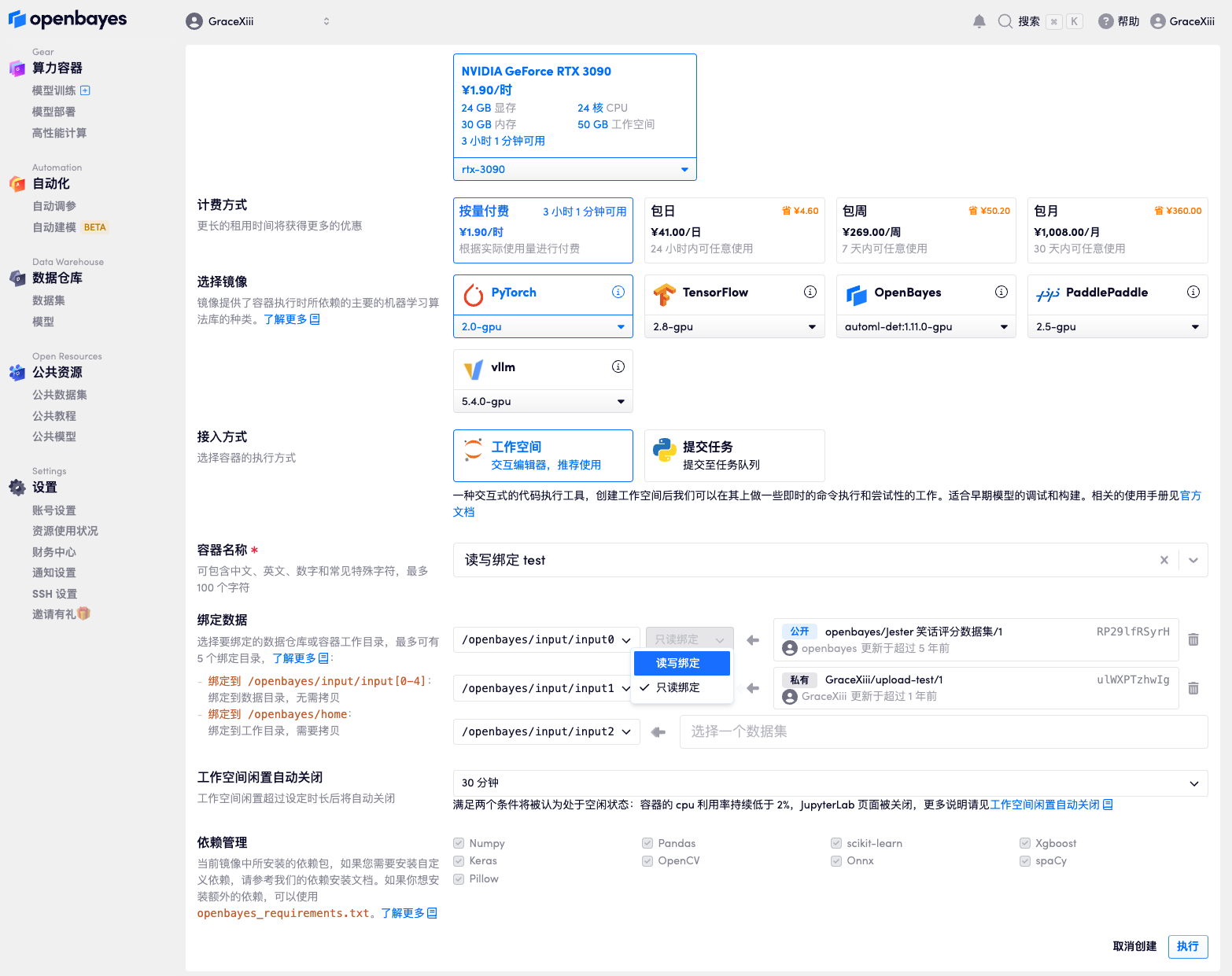
除了工作目录之外,你还可以在创建容器时选择将数据绑定到以下根目录:
/openbayes/input/input0/openbayes/input/input1/openbayes/input/input2/openbayes/input/input3/openbayes/input/input4
路径对应关系速查
为了避免把“容器里的真实目录”和“创建 Job 时填写的挂载路径”混在一起,可以先记住下面这组对应关系:
/output等价于/openbayes/home/input0等价于/openbayes/input/input0/input1等价于/openbayes/input/input1/input2等价于/openbayes/input/input2/input3等价于/openbayes/input/input3/input4等价于/openbayes/input/input4
其中最重要的是两类目录:
- 工作目录:
/output或/openbayes/home - 输入目录:
/input0~/input4或/openbayes/input/input0~/openbayes/input/input4
你可以把它理解为:
/output//openbayes/home是“当前这次执行自己的工作区”/input*//openbayes/input/input*是“挂载进来的外部数据入口”
一个典型场景如下:
读取训练数据: /input0/train.csv
读取预训练模型: /input1/model.bin
保存训练结果: /output/checkpoints/
保存最终模型: /output/final-model/
如果你在命令、Notebook 或代码里看到两套写法,不必困惑,它们只是同一批目录的两种表示方式。
数据绑定格式说明
在 Job 或 Workspace 中,一个数据绑定通常由两个核心字段组成:
name:绑定源标识,用来确定绑定的是哪个数据集或哪个 Job 输出path:绑定到容器中的挂载路径
name 的格式
常见的绑定源有两类:
-
数据集版本:
<owner>/<dataset-ref>/<version>例如:
alice/mnist/3 -
Job 输出:
<owner>/jobs/<job-ref>/output例如:
alice/jobs/preprocess-job/output
其中:
owner:资源所属用户名dataset-ref:数据集标识,推荐使用数据集 IDjob-ref:Job 标识,推荐使用 Job IDversion:数据集版本号,通常为数字
如果你是在页面中选择数据绑定,系统会自动填充可用标识;如果你是手工编写 CLI、YAML 或 API 参数,推荐优先使用 ID,而不是名称,以避免空格、转义或歧义问题。
path 的格式
支持的挂载路径如下:
/output/input0/input1/input2/input3/input4
其中:
/output表示工作目录,对应容器内的/openbayes/home/input0~/input4表示只挂载数据的输入目录
更直白地说:
- 需要把本次执行产生的代码、模型、日志整理结果长期保留下来时,优先写到
/output - 需要读取数据集、模型仓库、其他 Job 的产物时,通常挂到
/input* - 如果只是消费数据,不建议把大数据直接拷贝到
/output,否则会增加工作目录体积和后续重启成本
同时也兼容 openbayes 路径写法,例如可以把 /output 写成 /openbayes/home,把 /input0 写成 /openbayes/input/input0。其余路径与上文“路径对应关系速查”一一对应。
同一个 Job 请求里,挂载路径不能重复;例如不能同时把两个不同的绑定都挂载到 /input0。
数据目录的绑定有两种模式:
- 读写(read-write)绑定:允许你对绑定的数据进行添加、更新、删除操作。
- 只读(read-only)绑定:你只能读取绑定的数据,无法进行添加、更新、删除操作。
读写绑定
对于具有读写权限的数据集或模型,你可以选择「读写绑定」。此模式下,你可以直接访问对应的目录并更新数据。以下场景适合使用读写绑定:
- 对上传的原始数据集进行预处理,删除不需要的数据。
- 绑定两个数据集,从一个数据集中抽取部分数据,然后保存到另一个数据集中。
- 创建一个空的数据集版本,然后将容器中的数据保存到其中。
- 创建一个空的数据集版本,然后使用 rsync 命令将本地的数据复制到其中。
只有拥有读写权限的数据集或模型才能进行读写绑定。对于没有读写权限的公共数据集,以及其他执行的工作目录,你只能进行「只读」绑定。
-
大数据集处理
- 当需要处理的数据超过工作空间(
/openbayes/home)容量限制时 - 创建一个空的数据集,以读写方式绑定到 input 目录
- 直接将处理结果写入到绑定目录,避免占用工作空间
- 当需要处理的数据超过工作空间(
-
数据持久化
- 对于需要长期保存的重要数据
- 对于需要在多个容器之间共享的数据
- 建议创建专门的数据集进行管理,而不是存放在工作目录
-
性能考虑
- 读写绑定的数据会直接写入数据仓库,不会占用工作空间
- 适合需要频繁读写的大型数据集
- 可以避免容器关闭时的数据同步开销
只读绑定
对于没有读写权限的公开数据集、公开模型、以及其他人创建的公开教程等,你只能进行「只读绑定」。此模式下,你只能读取数据,无法进行添加、更新、删除操作。
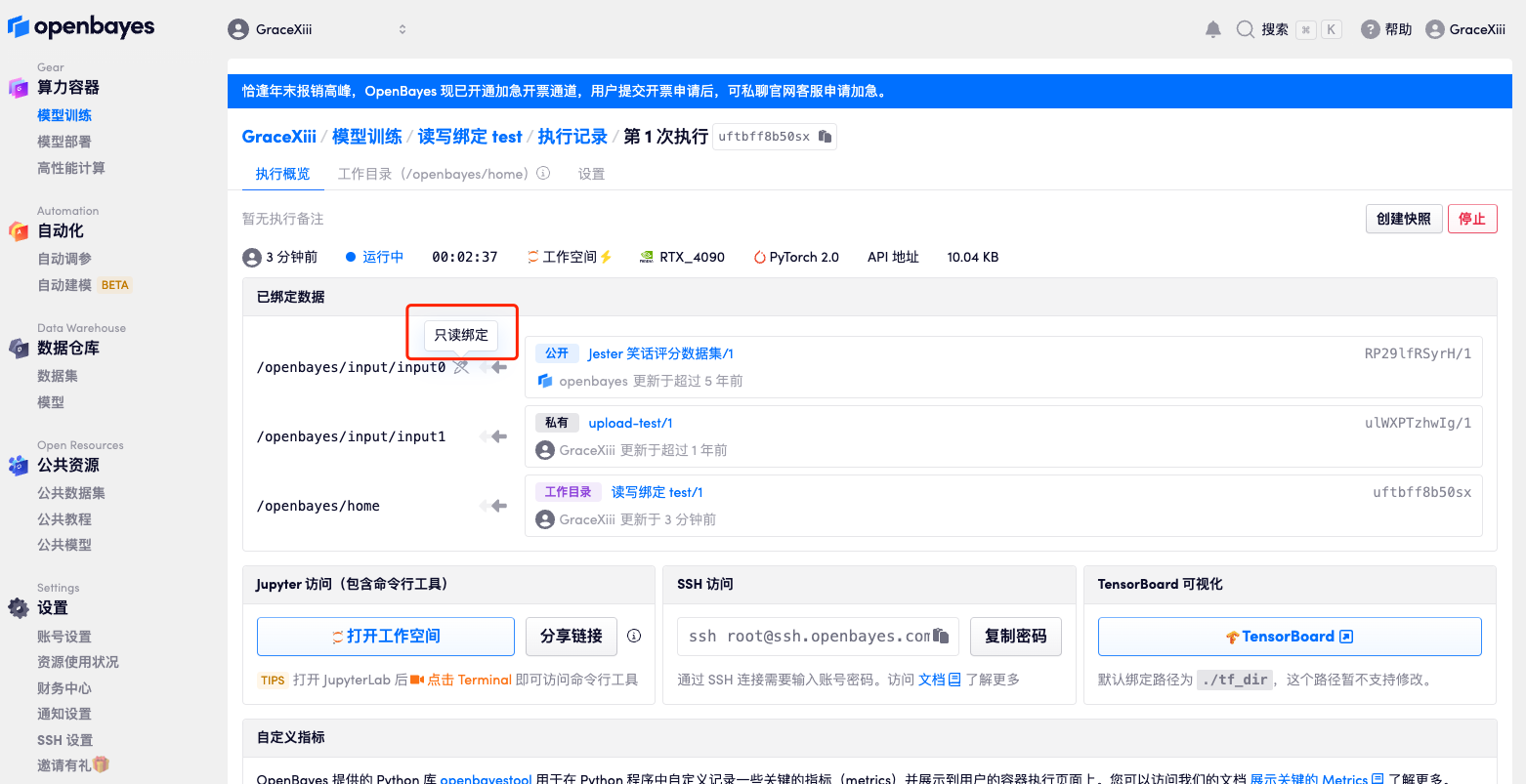
如上图所示,对于只读绑定的数据,容器创建页面会显示相应的提示信息。